In this article, I will explain how merge replication works.
Prerequisites
In merge replication, the following two jobs are working. To understand merge replication, it is essential to grasp the roles of these jobs.
Snapshot Agent
The Snapshot Agent creates an initial snapshot of the schema and data at the Publisher. This snapshot is applied to the Subscribers as the starting point for replication. It is typically used for the initial synchronization.
Merge Agent
The Merge Agent is the core component of merge replication, responsible for ongoing synchronization between the publisher and subscriber. It detects and resolves data changes made at both ends (publisher and subscriber) and merges the changes to ensure data consistency.
Transaction Replication vs. Merge Replication
In the following article, I wrote about how Transactional Replication works.

Transaction Replication is a “one-way” synchronization method. In other words, changes made in the publication database are reflected in the subscription database. On the other hand, Merge Replication is a “two-way” replication method. This means that changes made in the publication database are reflected in the subscription database, and changes made in the subscription database are reflected in the publication database.
To summarize, it can be described as follows:
Transaction Replication:
- Data Flow: One-way, from Publisher to Subscriber.
- Use Case: Ideal for scenarios where changes at the Publisher need to be quickly reflected at Subscribers, like reporting.
- Synchronization: Near real-time, as changes are continuously streamed to Subscribers.
- Conflict Handling: No conflicts, since updates to the subscription database are typically not allowed.
- Implementation: Involves Log Reader Agent, which reads changes from the transaction log, and Distribution Agent, which applies changes to Subscribers.
Merge Replication:
- Data Flow: Two-way, between Publisher and Subscribers.
- Use Case: Best for scenarios where data changes can happen at multiple locations, like occasionally connected systems or distributed applications.
- Synchronization: Periodic, based on scheduled intervals or manual triggers, merging changes from all parties.
- Conflict Handling: Built-in conflict resolution, as changes might occur at both Publisher and Subscribers.
- Implementation: Involves Snapshot Agent for initialization and Merge Agent for ongoing synchronization and conflict resolution.
Overview
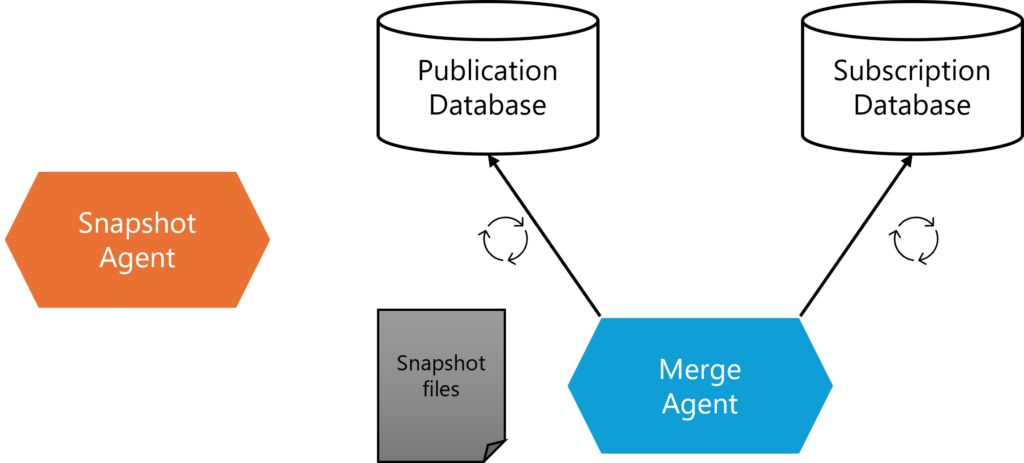
Merge replication works as illustrated in the following diagram.
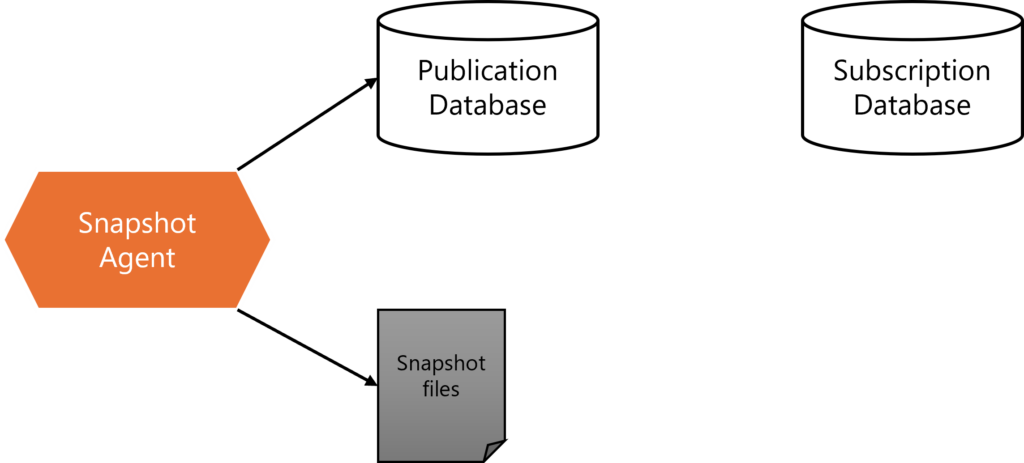
1. Snapshot Agent creates snapshot files.
The snapshot files include the schema and data from the Publisher database, which serve as the starting point for initializing the Subscriber database.
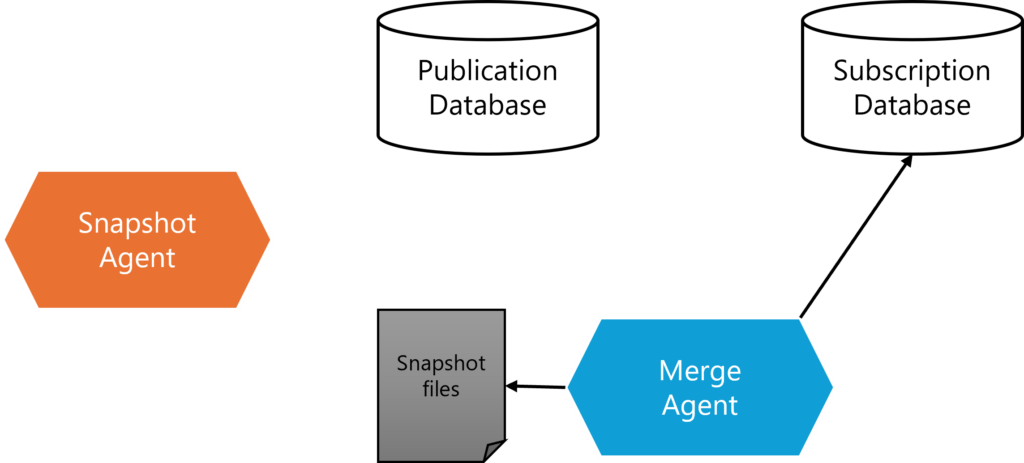
2. Merge Agent applies the snapshot files to the Subscriber database.
The Merge Agent transfers the snapshot files and initializes the Subscriber database with the schema and data from the Publisher.
3. Merge Agent tracks changes at both the Publisher and Subscriber.
Changes made at the Publisher and Subscriber are tracked using rowguid columns and system tables to ensure all modifications are captured.
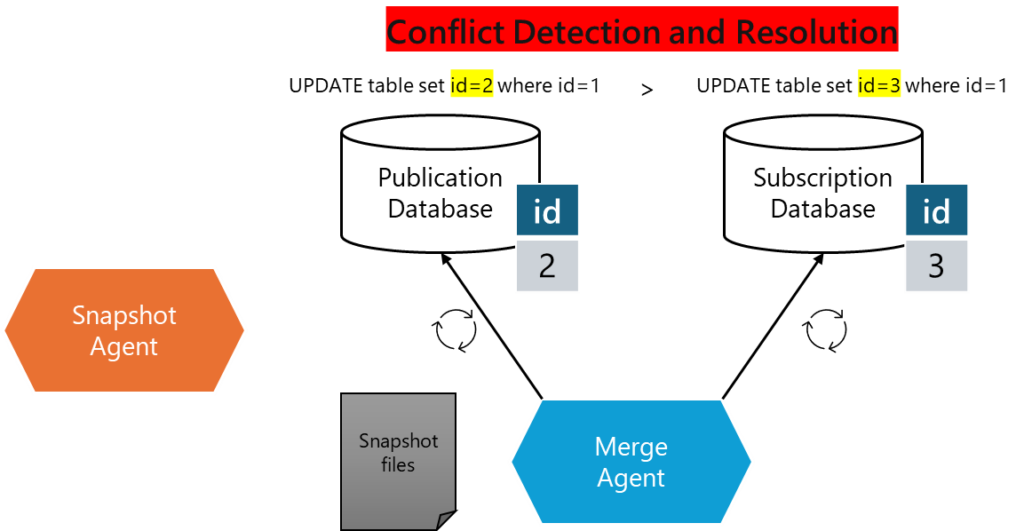
4. Merge Agent detects conflicts and resolves them.
If the same data is modified at both the Publisher and Subscriber, the Merge Agent detects the conflict. The Merge Agent resolves conflicts using predefined conflict resolution rules (e.g., priority-based or custom rules).
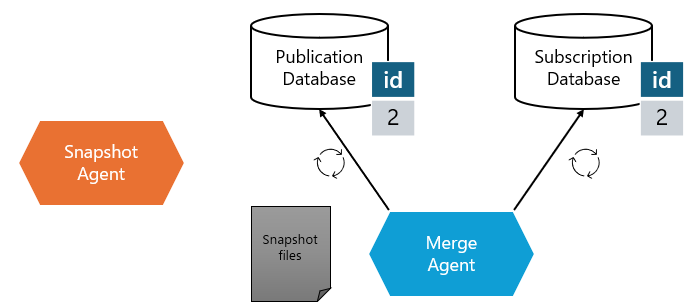
5. Merge Agent synchronizes changes.
After resolving conflicts, the Merge Agent updates the Publisher and Subscriber databases to ensure they have consistent data.
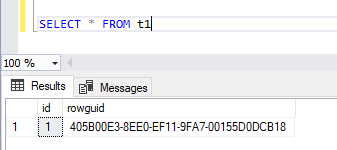
Detailed work
When you set up merge replication, a rowguid column is automatically added to the table being replicated. This column is used to track changes.
In addition, the GUID is also recorded in internal tables to help manage replication. This plays an important role in tracking data changes across the system.
- Insert/Update:
When rows are inserted or updated, the relevant information for the affected rows is stored in the MSmerge_contents table. This table holds metadata such as the unique GUID for each row, change generation numbers, and other details that the merge replication engine uses to synchronize data across all nodes efficiently. - Delete:
When rows are deleted, the information about the deleted rows is recorded in the MSmerge_tombstone table. This ensures that deletions are properly tracked and replicated across the system, allowing the replication process to mark the corresponding rows as deleted in other databases.
SELECT * FROM MSmerge_contents
SELECT * FROM MSmerge_tombstone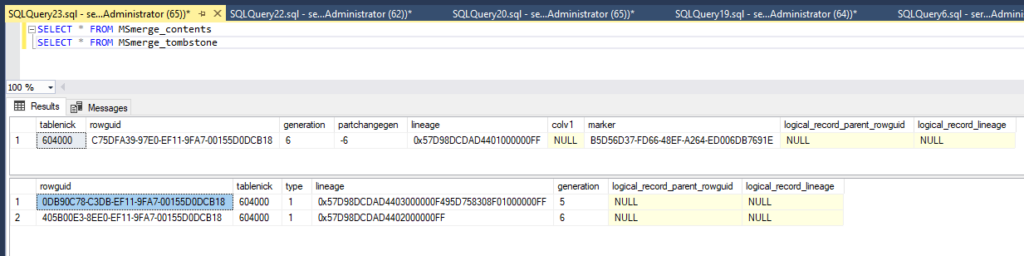
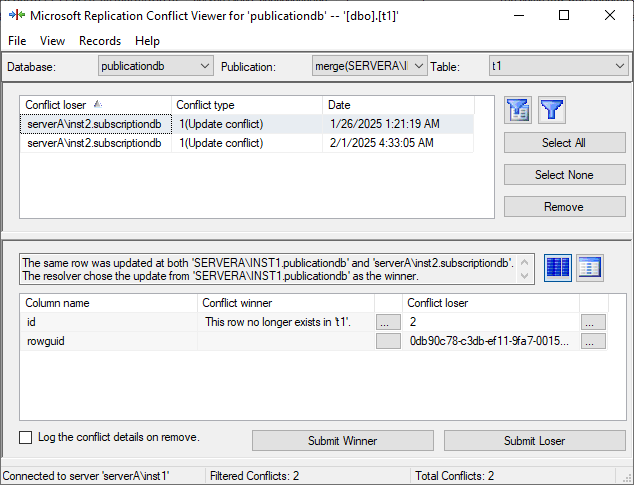
In merge replication, not only are update and deletion events tracked, but the rowguid values are also recorded when conflicts occur. When the merge replication process detects a conflict, detailed information is recorded for later analysis and resolution. This information is stored in the MSmerge_conflicts_info table, which includes:
Rowguid: The unique identifier of the affected row.
Conflict Type: Information on whether the conflict involves an update, delete, or a combination of operations.
Reason Text: The reasons for why conflicts occur are recorded.
SELECT * FROM MSmerge_conflicts_info
Additionally, conflict information can also be viewed through SSMS. When using merge replication, conflicts are expected to occur, so it is beneficial to regularly review the extent of these conflicts and how they have been resolved.